Worker Pool 및 Pipeline
Worker Pool
Worker Pool은 동일한 작업을 여러 인스턴스로 분배하여 병렬적으로 처리하는 패턴이다. Go에서는 동일한 작업을 하는 여러 고루틴에 입력을 달리하여 작업을 분배하는 방식으로 구현된다. 특히 채널의 존재가 Worker Pool을 구현하는데 큰 도움이 된다.
필요할 때마다 고루틴을 생성하는 것보다 Worker Pool을 사용하는 것이 효율적인 이유는 작업자 고루틴의 Initialize 비용을 아끼고 생성된 고루틴을 재사용하기 때문이다. 또한 잠재적으로 생성될 수 있는 고루틴의 수를 제한하여 성능상의 이점을 얻을 수 있다.
만약 서버에서 요청이 도착할 때마다 고루틴을 생성한다면, 요청이 많아질수록 고루틴의 수도 증가하게 된다. 요청이 burst 형태로 발생한다면 파일을 열고 있는 고루틴이 수천개 생성될 수도 있다. Worker Pool을 통해 고루틴의 수를 제한하면 이러한 문제를 해결할 수 있다.
간단한 예제를 통해 Worker Pool에 대해 알아보려 한다. 이 예제는 디렉토리를 순회하며 정규식 일치 여부를 확인하는 프로그램이다.
type Work struct {
file string
pattern *regexp.Regexp
}
func main() {
jobs := make(chan Work)
wg := sync.WaitGroup{}
for i := 0; i < 3; i++ {
wg.Add(1)
go func() {
defer wg.Done()
worker(jobs)
}()
}
...
}대부분의 시스템에서 열 수 있는 파일의 수는 제한되어 있기 때문에 고루틴의 수를 제한하는 것이 좋다.
위의 예제에서는 3개의 고루틴을 생성하고, sync.WaitGroup을 사용하여 처리가 완료될 때까지 기다리도록 한다.
또한 익명 함수를 통해 실제 작업 함수를 sync.WaitGroup의 로직으로부터 분리하였다.
func main() {
...
rex, err := regexp.Compile(os.Args[2])
if err != nil {
panic(err)
}
filepath.Walk(os.Args[1], func(path string, d fs.FileInfo, err error) error {
if err != nil {
return err
}
if !d.IsDir() {
jobs <- Work{path, rex}
}
return nil
})
close(jobs)
wg.Wait()
}main 함수의 나머지 부분에서는 디렉토리를 순회하며 파일을 읽어들이고, jobs 채널을 통해 worker에게 작업을 전송한다.
이후 close 함수를 통해 jobs 채널을 닫고, wg.Wait() 함수를 통해 모든 고루틴이 종료될 때까지 기다린다.
func worker(jobs chan Work) {
for work := range jobs {
f, err := os.Open(work.file)
if err != nil {
fmt.Println(err)
continue
}
scn := bufio.NewScanner(f)
lineNum := 1
for scn.Scan() {
result := work.pattern.Find(scn.Bytes())
if len(result) > 0 {
fmt.Printf("%s:#%d: %s\n", work.file, lineNum, string(result))
}
lineNum++
}
f.Close()
}
}프로그램이 실행되면 main 함수에서 3개의 worker 고루틴이 생성된다.
이후 각 파일을 순회하며 파일 정보가 jobs 채널로 전송되고, worker 함수는 jobs 채널을 통해 전달받은 작업을 처리한다.
이 때 worker 함수는 한 시점에 최대 3개 존재할 수 있으며, 동시에 처리되기 때문에 작업은 인터리빙된다.
현재 작업의 결과를 worker 함수가 직접 출력하고 있지만, 일반적으로 그보다는 Worker Pool에서 작업 결과를 다시 가져오는 경우가 많다.
이를 구현하는 방법 중 하나로 Work 구조체 자체에 결과를 반환할 채널을 포함시키는 방법이 있다.
type Work struct {
file string
pattern *regexp.Regexp
result chan Result
}
type Result struct {
fileName string
lineNum int
text string
}그렇다면 worker 함수가 작업 결과물을 결과 채널에 전송하도록 수정해야 한다.
func worker(jobs <-chan Work) {
for work := range jobs {
f, err := os.Open(work.file)
if err != nil {
fmt.Println(err)
continue
}
scn := bufio.NewScanner(f)
lineNum := 1
for scn.Scan() {
result := work.pattern.Find(scn.Bytes())
if len(result) > 0 {
work.result <- Result{
fileName: work.file,
lineNum: lineNum,
text: string(result),
}
}
lineNum++
}
f.Close()
}
}이렇게 하면 인터리빙된 작업 결과의 출력을 다시 하나의 고루틴에서 처리할 수 있다.
이 때 주의할 점은 Worker Pool에 작업을 전달하는 고루틴과 작업 결과를 수신하는 고루틴이 서로 다른 고루틴어야 한다는 것이다.
만약 같은 고루틴에서 작업을 전달하고 작업 결과를 수신하면 데드락이 발생할 수 있다.
가령 위 예제의 main 함수에서 작업 결과를 수신하려 한다면 데드락이 발생할 것이다.
따라서 디렉토리를 순회하는 코드를 별도의 고루틴으로 분리하고, 메인 고루틴에서 작업 결과를 수신하도록 할 것이다.
그렇다면 작업 결과를 수신하는 고루틴은 결과 채널에 대해 알 수 있을까? 조금 복잡해지지만 결과 채널 자체를 채널로 감싸서 전달하는 방식을 사용하면 된다.
allResults := make(chan chan Result)worker 고루틴은 채널을 생성하여 allResults 채널에 전달한 뒤 그 채널에 작업 결과를 전달한다.
메인 고루틴은 allResults 채널로부터 결과 채널을 전달받은 뒤, 해당 채널을 이터레이트하여 작업 결과를 수신한다.
worker 고루틴이 전송을 완료하면 해당 채널을 닫을 것이고, 이를 통해 메인 고루틴의 이터레이션도 종료될 것이다. 그렇다면 메인 고루틴은 allResults 채널에서 다음 결과 채널을 전달받아 이터레이션을 다시 시작할 것이다.
디렉토리 순회가 분리된 메인 고루틴으로부터 분리되고, 채널을 수신받아 결과를 출력한다. 이 내용이 반영된 main함수는 다음과 같다.
func main() {
jobs := make(chan Work)
wg := sync.WaitGroup{}
for i := 0; i < 3; i++ {
wg.Add(1)
go func() {
defer wg.Done()
worker(jobs)
}()
}
rex, err := regexp.Compile(os.Args[2])
if err != nil {
panic(err)
}
allResults := make(chan chan Result)
go func() {
defer close(allResults)
filepath.Walk(os.Args[1], func(path string, d fs.FileInfo, err error) error {
if err != nil {
return err
}
if !d.IsDir() {
ch := make(chan Result)
jobs <- Work{path, rex, ch}
allResults <- ch
}
return nil
})
}()
for resultCh := range allResults {
for result := range resultCh {
fmt.Printf("%s:%d:%s\n", result.fileName, result.lineNum, result.text)
}
}
close(jobs)
wg.Wait()
}Worker Pool을 통해, javascript의 Promise처럼 결과가 나중에 사용될 작업을 수행할 수도 있다.
resultCh := make(chan Result)
jobs <- Work{
file: "someFile",
pattern: somePattern,
ch: resultCh,
}
// do something else
for result := range <-reseultCh {
// do something with result
}Pipeline
많은 경우 작업은 여러 단계로 나누어지고 각 단계의 결과를 변환 및 강화하는 과정을 거친다. 그리고 일반적으로 일련의 데이터를 획득하는 초기 단계가 존재하며, 단계를 거칠수록 원본 데이터와 거리가 멀어진다. 대표적인 예가 이미지 처리 파이프라인이다. 원본 이미지가 디코딩, 변환, 크롭, 리사이징, 인코딩 등을 거쳐 새로운 이미지가 생성된다.
대부분의 데이터 프로세싱 애플리케이션은 많은 양의 데이터를 처리하므로, 성능상의 이점을 위해 동시성을 지원하는 파이프라인을 사용한다.
이 챕터에서는 CSV파일을 읽고 처리하는 파이프라인 예제를 작성해보려 한다. CSV 파일 안의 사람들의 키, 몸무게가 인치, 파운드 단위로 저장되어 있다고 가정하자. 우리는 이를 센티미터, 킬로그램 단위로 변환하고 JSON 형태로 출력할 것이다.
먼저 Record 구조체를 정의한다.
type Record struct {
Row int
Height float64
Weight float64
}파이프라인은 세 단계로 구성된다. 첫 번째 단계는 CSV 파일에서 데이터를 읽어 Record 구조체로 변환하는 단계이다.
func newRecord(in []string) (Record, error) {
row, err := strconv.Atoi(in[0])
if err != nil {
return Record{}, err
}
height, err := strconv.ParseFloat(in[1], 64)
if err != nil {
return Record{}, err
}
weight, err := strconv.ParseFloat(in[2], 64)
if err != nil {
return Record{}, err
}
return Record{
Row: row,
Height: height,
Weight: weight,
}, nil
}
func parse(input []string) Record {
record, err := newRecord(input)
if err != nil {
panic(err)
}
return record
}두 번째 단계는 Record 구조체를 받아 센티미터, 킬로그램 단위로 변환한다.
func convert(input Record) Record {
input.Height = input.Height * 2.54
input.Weight = input.Weight * 0.45359237
return input
}마지막 단계는 Record 구조체를 받아 JSON 형태로 변환한다.
func encode(input Record) []byte {
data, err := json.Marshal(input)
if err != nil {
panic(err)
}
return data
}이제 파이프라인을 조립하면 되는데, 가장 직관적인 방식은 동기 파이프라인(Synchronous Pipeline)을 구성하는 것이다.
func syncPipeline(input *csv.Reader) {
input.Read() // skip header
for {
rec, err := input.Read()
if err == io.EOF {
return
}
if err != nil {
panic(err)
}
out := encode(convert(parse(rec)))
fmt.Println(string(out))
}
}그런데 이 동기 파이프라인은 문제가 있다. 파이프라인 전체가 한 단위로 실행되기 때문에, 파이프라인의 각 단계가 동시에 실행되지 않는다. 각 단계가 인터리빙되지 않기 때문에 파이프라인의 성능은 전체 단계의 성능에 의존하게 된다.
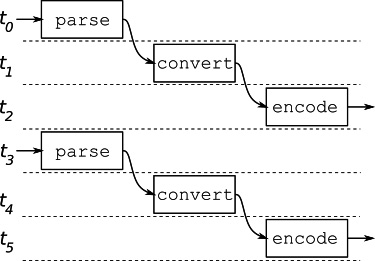
비동기 파이프라인
비동기 파이프라인에서는 각 단계가 별도의 고루틴에서 실행되며, 각 단계는 채널을 통해 데이터를 전달한다. 또한 입력 채널이 닫히면 출력 채널도 닫히도록 하여 연쇄적으로 채널이 닫히도록 하여 파이프라인을 종료한다.
각각의 단계가 별도의 고루틴에서 실행되기 때문에, 각 단계는 동시에 실행될 수 있다. 따라서 파이프라인의 성능은 가장 느린 단계의 성능에 의존하며, 전체 단계의 성능에 의존하지 않기 때문에 동기 파이프라인보다 더 좋은 성능을 보인다.
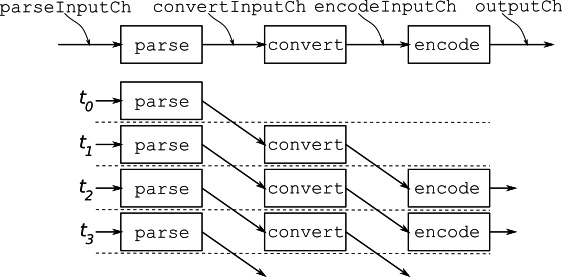
파이프라인의 각 단계를 연결하는 제네릭 함수를 작성한다.
func pipelineStage[IN any, OUT any](input <-chan IN, output chan<- OUT, process func(IN) OUT) {
defer close(output)
for data := range input {
output <- process(data)
}
}각각 IN 및 OUT 타입 파라미터가 채널 및 함수 입출력과 어떻게 매칭되어 있는지 확인하자.
이어서 비동기 파이프라인을 구성한다. 각 단계가 채널을 통해 데이터를 전달하기 때문에, 동기 파이프라인 함수보다는 좀 더 복잡하다.
func asyncPipeline(input *csv.Reader) {
parseInputCh := make(chan []string)
convertInputCh := make(chan Record)
encodeInputCh := make(chan Record)
outputCh := make(chan []byte)
done := make(chan struct{})
go pipelineStage(parseInputCh, convertInputCh, parse)
go pipelineStage(convertInputCh, encodeInputCh, convert)
go pipelineStage(encodeInputCh, outputCh, encode)
go func() {
for data := range outputCh {
fmt.Println(string(data))
}
close(done)
}()
input.Read() // skip header
for {
rec, err := input.Read()
if err == io.EOF {
close(parseInputCh)
break
}
if err != nil {
panic(err)
}
parseInputCh <- rec
}
<-done
}파이프라인은 Worker Pool이 채널을 통해 연결된 형태라고도 볼 수 있다. 실제로 각 단계는 Worker Pool로 구현이 가능하기 때문에, 오래 걸리는 특정 단계의 Worker 수를 늘리는 등의 최적화가 가능하다.
Fan-out, Fan-in
가령 다음과 같이 파이프라이닝된 작업이 있다고 가정하자.
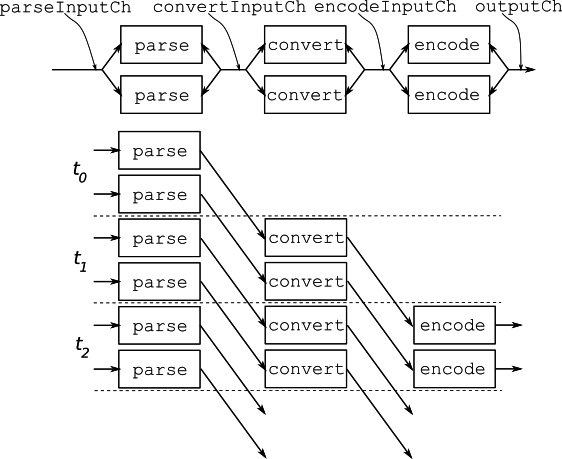
모든 worker가 병렬적으로 실행되며, 각 단계마다 두 개의 worker가 실행되고 있다.
이 디자인에서 파이프라인의 각 단계는 Shared Channel을 통해 통신한다. 따라서 여러 고루틴이 동일한 입력 채널에서 읽고(Fan-out), 출력 채널을 통해 데이터를 전달한다(Fan-in).
이와 같은 파이프라인을 설계하려면 이전에 작성한 제네릭 함수를 수정해야 한다.
이전의 함수는 입력 채널이 닫히면 출력 채널도 닫히도록 구현되어 있어, 입력 채널이 닫히면 순서대로 출력 채널도 닫히게 된다.
하지만 worker의 수가 늘어나면 이미 닫은 출력 채널을 다시 닫으려고 하기 때문에 panic이 발생할 것이다.
따라서 모든 worker가 종료될 때까지 출력 채널을 닫지 않도록 sync.WaitGroup을 사용하게끔 수정해야 한다.
func workerPoolpipelineStage[IN any, OUT any](input <-chan IN, output chan<- OUT, process func(IN) OUT, numWorkers int) {
defer close(output)
wg := sync.WaitGroup{}
for i := 0; i < numWorkers; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for data := range input {
output <- process(data)
}
}()
}
wg.Wait()
}입력 채널이 닫히면 각 파이프라인 단계의 worker가 종료될 것이고, WaitGroup에 의해 모든 worker가 종료될 때까지 기다린 뒤 출력 채널을 닫는다.
파라미터가 추가되었으니, 파이프라인 설정 함수에서 변경된 사항을 반영해야 한다.
const numWorkers = 2
go workerPoolpipelineStage(parseInputCh, convertInputCh, parse, numWorkers)
go workerPoolpipelineStage(convertInputCh, encodeInputCh, convert, numWorkers)
go workerPoolpipelineStage(encodeInputCh, outputCh, encode, numWorkers)이제 이 파이프라인을 실행해보자.
$ go run csv.go
...
{"Row":66,"Height":142.24,"Weight":101.15109851000001}
{"Row":65,"Height":172.72,"Weight":97.52235955}
{"Row":68,"Height":152.4,"Weight":80.28584949}
{"Row":67,"Height":162.56,"Weight":104.77983747}
{"Row":69,"Height":139.7,"Weight":86.63614267}
...출력 순서가 뒤죽박죽이다. 이는 각 단계의 worker가 병렬적으로 실행되기 때문이다. 즉, 비동기 파이프라이닝이 잘 동작하고 있다는 것을 의미한다!
지금의 파이프라인은 각 단계의 worker가 공유된 채널을 통해 통신하고 있다. 따라서 결과가 인터리빙되서 출력되므로 정렬된 순서를 보장할 수 없다. 각 단계의 고루틴이 전용 채널을 사용한다면 정렬된 순서를 보장할 수 있다. 이러한 디자인은 파이프라인의 일부 단계가 특히 처리량이 많이 필요하여, worker를 여러 개 두고 싶을 때 유용하다.
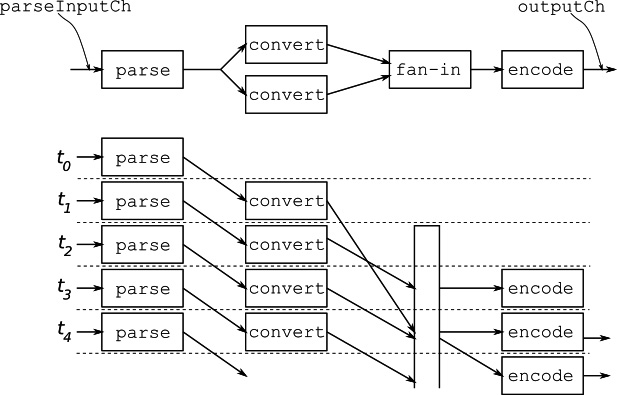
위 그림처럼 특정 단계의 결과가 전용 채널을 통해 전달되므로, 데이터를 fan-in 및 정렬하는 단계가 필요하다. 따라서 입력 채널과 done 채널을 받고 출력 채널을 반환하는 제네릭 함수를 작성한다. 이를 통해 한 고루틴의 출력을 다른 고루틴의 입력으로 전달할 수 있다.
func cancelablePipelineStage[IN any, OUT any](input <-chan IN, output chan<- OUT, done <-chan struct{}, process func(IN) OUT) <-chan OUT {
outputCh := make(chan OUT)
go func() {
for {
select {
case data, ok := <-input:
if !ok {
close(outputCh)
return
}
outputCh <- process(data)
case <-done:
return
}
}
}()
return outputCh
}또한 제네릭 fan-in 함수를 작성한다.
func fanIn[T any](done <-chan struct{}, channels ...<-chan T) <-chan T {
outputCh := make(chan T)
wg := sync.WaitGroup{}
for _, ch := range channels {
wg.Add(1)
go func(input <-chan T) {
defer wg.Done()
for {
select {
case data, ok := <-input:
if !ok {
return
}
outputCh <- data
case <-done:
return
}
}
}(ch)
}
go func() {
wg.Wait()
close(outputCh)
}()
return outputCh
}fanIn 함수는 여러 채널에서 받은 데이터를 병럴적으로 출력 채널에 전달한다. 이 때 아직까지는 입력 순서대로 출력 채널에 전달되지는 않는다.
select문을 사용하는 경우 고정된 개수의 채널을 사용해야 한다. 반면 위의 경우처럼 채널의 Slice를 select하는 경우에는reflect.Select를 사용할 수 있다. 찾아보니reflect.Select는 reflect 패키지 특성상 어쩔 수 없이 성능이 좀 떨어지는 모양이니, 위 방법을 사용하는 것이 좋을 것 같다.
파이프라인을 설정하는 함수도 다음과 같이 변경해준다.
func fanInPipeline(input *csv.Reader) {
parseInputCh := make(chan []string)
done := make(chan struct{})
convertInputCh := cancelablePipelineStage(parseInputCh, done, parse)
const numWorkers = 2
fanInCh := make([]<-chan Record, 0)
for i := 0; i < numWorkers; i++ {
convertOutputCh := cancelablePipelineStage(convertInputCh, done, convert)
fanInCh = append(fanInCh, convertOutputCh)
}
convertOutputCh := fanIn(done, fanInCh...)
outputCh := cancelablePipelineStage(convertOutputCh, done, encode)
go func() {
for data := range outputCh {
fmt.Println(string(data))
}
close(done)
}()
input.Read() // skip header
for {
rec, err := input.Read()
if err == io.EOF {
close(parseInputCh)
break
}
if err != nil {
panic(err)
}
parseInputCh <- rec
}
<-done
}이제 파이프라인의 변환 단계에서 worker가 두 개 돌 것이다.
순서 보장
순서를 보장하면서 fan-in을 구현하는 방법의 핵심은 순서를 벗어난 데이터를 버퍼링하는 것이다.
fan-in을 처리하는 고루틴은 여러 고루틴으로부터 채널을 통해 데이터를 읽고, 이를 출력 채널에 전달한다. 이때 한 고루틴으로부터 순서에서 벗어난 데이터를 읽으면, 다른 고루틴에서 순서가 맞는 데이터가 언젠가 읽힐 것을 알 수 있다. 따라서 순서에서 벗어난 데이터를 버퍼링하고, 순서가 맞는 데이터가 읽힐 때까지 기다린 뒤 버퍼링된 데이터를 순서에 맞춰 출력 채널에 전달하면 된다.
순서에서 벗어난 데이터를 받으면 해당 데이터를 전송한 고루틴을 일시적으로 정지시킬 필요가 있는데, 이는 pause라는 추가적인 채널을 통해 구현한다.
먼저 Record의 순서를 얻기 위한 인터페이스와 메소드를 작성한다.
type sequenced interface {
Sequence() int
}
func (r Record) Sequence() int {
return r.Row
}또한 데이터의 정렬 및 고루틴 일시 정지를 위한 구조체를 작성한다.
type fanInRecord[T sequenced] struct {
index int
data T
pause chan struct{}
}이후 각 입력 채널에 대해 고루틴을 생성하고, 해당 고루틴은 채널에서 데이터를 읽어들인 뒤 fanInRecord 인스턴스를 생성하여 다시 채널로 전송한다.
전송하는 데이터의 정렬 여부는 해당 고루틴에서 판단하지 않고, 다음 단계에서 판단한다.
pause 채널에 의해 고루틴이 일시 정지될 것이고, 판단 결과에 따라 블로킹된 고루틴을 다시 시작시킬 것이다.
또한 이전 예제들과 마찬가지로 입력 채널이 닫히면 출력 채널도 닫히도록 구현한다.
func orderedFanIn[T sequenced](done <-chan struct{}, channels ...<-chan T) <-chan T {
fanInCh := make(chan fanInRecord[T])
wg := sync.WaitGroup{}
for i := range channels {
wg.Add(1)
pauseCh := make(chan struct{})
go func(pause chan struct{}, index int) {
defer wg.Done()
for {
var ok bool
var data T
select {
case data, ok = <-channels[index]:
if !ok {
return
}
fanInCh <- fanInRecord[T]{index: index, data: data, pause: pause}
case <-done:
return
}
select {
case <-pause:
case <-done:
return
}
}
}(pauseCh, i)
}
go func() {
wg.Wait()
close(fanInCh)
}()
...
}orderedFanIn 함수의 나머지 부분은 정렬 로직이 작성된다.
채널로부터 순서를 벗어난 데이터를 읽으면, 해당 데이터를 큐에 저장해두고 일시 정지시킨다.
그리고 채널로부터 순서가 맞는 데이터를 읽으면 큐에 저장된 데이터를 꺼내 출력 채널에 전달한다.
func orderedFanIn[T sequenced](done <-chan struct{}, channels ...<-chan T) <-chan T {
...
outputCh := make(chan T)
go func() {
defer close(outputCh)
expected := 1
queuedData := make([]*fanInRecord[T], len(channels))
for in := range fanInCh {
// 순서가 맞는 데이터는 바로 전달
if in.data.Sequence() == expected {
select {
case outputCh <- in.data:
in.pause <- struct{}{}
expected++
allDone := false
// 큐에 저장된 다음 데이터가 있는지 확인
for !allDone {
allDone = true
for i, d := range queuedData {
if d != nil && d.data.Sequence() == expected {
select {
case outputCh <- d.data:
queuedData[i] = nil
d.pause <- struct{}{}
expected++
allDone = false
case <-done:
return
}
}
}
}
case <-done:
return
}
} else {
// 순서가 맞지 않는 데이터는 큐에 일시 저장
in := in
queuedData[in.index] = &in
}
}
}()
return outputCh
}이와 같이 파이프라인은 특정한 요구사항에 따라 다양한 방식으로 구현되며, 모든 요구사항을 만족하는 하나의 범용적인 구현은 존재하지 않는다. 필요에 따라 적절한 방식의 파이프라인을 구현하고, 보틀넥이 발생하는 단계를 fan-on, fan-out 및 worker pool 조절 등으로 최적화하는 것이 중요하다. 하지만 동시성 코드와 계산 로직을 분리하여 설계하는 것이 중요하다는 것은 변함이 없다.
References
[
[Burak Serdar, 『Effective Concurrency in Go』, Packt Publishing](https://learning.oreilly.com/library/view/effective-concurrency-in/9781804619070/)